
تولید بیش از ۱۰,۰۰۰ کلمه با استفاده از مدلهای زبانی مبتنی بر متن طولانی
تولید محتوای طولانی و با کیفیت یکی از چالشهای مهم در حوزه یادگیری ماشین و هوش مصنوعی بهشمار میرود. مدلهای زبانی مبتنی بر متن طولانی، که قادر به پردازش و تولید مقادیر عظیمی از دادهها هستند، توانستهاند تحولی اساسی در نحوه تولید محتوا ایجاد کنند. این مدلها با استفاده از الگوریتمهای پیچیده و دادههای متنی وسیع، میتوانند متون بسیار طولانی و پیچیدهای را تولید کنند که از نظر دقت و کیفیت در سطح بالایی قرار دارند. هدف این مقاله بررسی فرآیند تولید محتوای طولانی با استفاده از این مدلها، بهبود مستمر آنها و ارزیابی کیفیت متون تولید شده است.
بررسی علت محدودیت در طول تولید خروجی مدلهای زبانی بزرگ (LLM)
یکی از مسائل چالشبرانگیز در زمینه مدلهای زبانی بزرگ (LLM)، محدودیت در طول تولید خروجی آنها است. بر اساس مقالهای که توسط نویسندگانی همچون Yushi Bai، Jiajie Zhang، و دیگران در تاریخ ۱۳ آگوست ۲۰۲۴ منتشر شده است، این موضوع مورد بررسی قرار گرفته و دلایل و راهحلهای ممکن برای رفع این محدودیت تحلیل شده است.
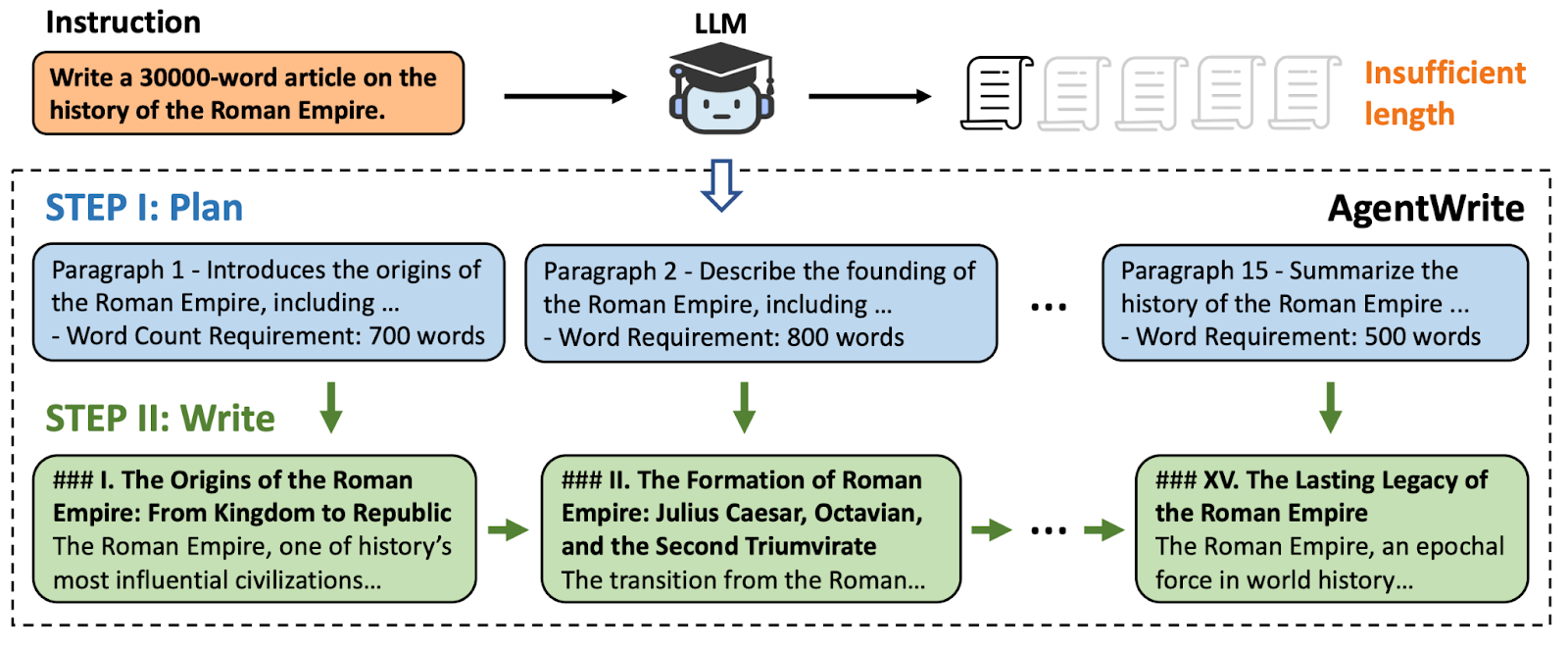
طراحی و اجرای ارزیابی LongWrite-Ruler
در مرحله اول برای بررسی طول حداکثر خروجی که یک مدل زبانی بزرگ (LLM) میتواند تولید کند، یک آزمون سبک طراحی کردند: آنها هشت دستور مختلف ایجاد کردند، چهار دستور به زبان چینی و چهار دستور به زبان انگلیسی، و نیازمندیهای طول خروجی “L” در این دستورات متغیر بود. به عنوان مثال: “یک مقاله L کلمهای درباره تاریخ امپراتوری روم بنویس”. در طول آزمون، از مقادیر L ∈ {۱۰۰۰، ۲۰۰۰، ۵۰۰۰، ۱۰۰۰۰، ۲۰۰۰۰، ۳۰۰۰۰} استفاده کردند که در مجموع ۴۸ دستور آزمون ایجاد شد.
نتایج ارزیابی و تحلیل آنها
نویسندگان در این آزمایشها به بررسی حداکثر طول خروجی چهار مدل منبعباز و چهار مدل اختصاصی پرداختند. برای مدلهای اختصاصی، پارامتر حداکثر توکنها بر اساس طول خروجی پشتیبانیشده توسط API آنها تنظیم شد و برای مدلهای منبعباز، این مقدار به ۳۲ هزار توکن تنظیم شد. نتایج نشان داد که حداکثر طول خروجی تولید شده توسط تمامی مدلها به طور معمول در حدود ۲۰۰۰ کلمه بود.
این آزمایش نشان داد که مدلهای اختصاصی نمیتوانند به حداکثر طول خروجی مورد انتظار خود دست یابند و با افزایش نیازمندی طول بیش از ۱۰۰۰۰ کلمه، حتی میانگین طول خروجی نیز کاهش مییابد. این مسئله بیانگر محدودیتهایی در توانایی مدلهای زبانی برای تولید متون با طولهای بسیار بلند است.
آزمایشهای کنترلشده و تحلیل آنها
برای بررسی دقیقتر علت این محدودیت، نویسندگان مجموعهای از آزمایشهای کنترلشده را اجرا کردند. در این آزمایشها، آنها از مدل GLM-4-9B به عنوان مدل پایه استفاده کردند و سه مجموعه داده مختلف را برای آموزش این مدل آماده کردند. این مجموعهها شامل دادههایی با حداکثر طول خروجی ۵۰۰، ۱۰۰۰، و ۲۰۰۰ کلمه بودند. پس از آموزش مدلها با این دادهها، حداکثر طول خروجی تولید شده توسط مدلها با استفاده از آزمون LongWrite-Ruler اندازهگیری شد.
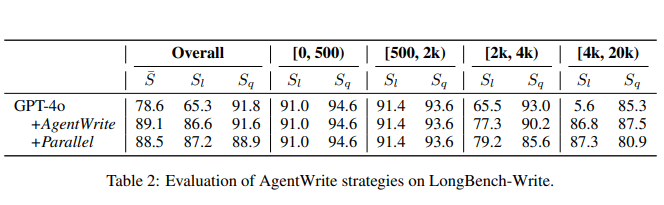
نتایج نشان داد که با افزایش طول حداکثر خروجی در دادههای آموزشی (SFT)، حداکثر طول خروجی مدل نیز افزایش مییابد. به عنوان مثال، مدلهایی که با دادههای حداکثر ۲۰۰۰ کلمه آموزش دیده بودند، توانستند خروجیهایی با طول ۱۸۰۰ کلمه تولید کنند. این نتایج به وضوح نشان میدهد که محدودیت طول خروجی مدلها به دلیل ناکافی بودن طول خروجی در دادههای SFT است.
محدودیتها و نتایج نهایی
یکی از نکات مهمی که در این مقاله به آن اشاره شده، این است که حتی با استفاده از دادههای ترکیبی تولیدشده توسط مدلهای زبانی (synthetic data)، نمیتوان بر این محدودیت غلبه کرد. دادههای تولید شده توسط مدلهای موجود همچنان نمیتوانند این محدودیت طول را بشکنند و این موضوع نشاندهنده اهمیت داشتن دادههای آموزشی با طولهای خروجی بلندتر در مرحله SFT است.
مدلهای مورد ارزیابی در این مقاله
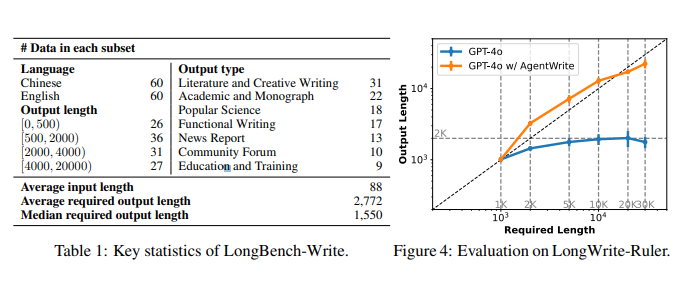
در این بخش، جزئیات مدلهایی که در این مطالعه مورد ارزیابی قرار گرفتهاند، در جدول ۵ ارائه شده است:
-
Claude 3.5 Sonnet (Anthropic, 2024)
- نسخه مدل: claude-3-5-sonnet-20240620
- پنجره متنی: ۲۰۰,۰۰۰ توکن
- حداکثر توکنهای خروجی: ۴,۰۹۶ توکن
-
GPT-4 Turbo (Achiam et al., 2023)
- نسخه مدل: gpt-4-turbo-2024-04-09
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: ۴,۰۹۶ توکن
-
GPT-4o mini (OpenAI, 2024b)
- نسخه مدل: gpt-4o-mini-2024-07-18
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: ۱۶,۳۸۴ توکن
-
GPT-4o (OpenAI, 2024a)
- نسخه مدل: gpt-4o-2024-05-13
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: ۴,۰۹۶ توکن
-
GLM-4-9B-chat (GLM et al., 2024)
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: مشخص نشده
-
Llama-3.1-8B-Instruct (Dubey et al., 2024)
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: مشخص نشده
-
Llama-3.1-70B-Instruct (Dubey et al., 2024)
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: مشخص نشده
-
Mistral-Large-Instruct (Jiang et al., 2023)
- نسخه مدل: Mistral-Large-Instruct-2407
- پنجره متنی: ۱۲۸,۰۰۰ توکن
- حداکثر توکنهای خروجی: مشخص نشده
آزمون LongWrite-Ruler
برای ارزیابی حداکثر طول خروجی مدلها در آزمون LongWriter-Ruler، از ۸ پرسش اولیه زیر استفاده شده است:
- نوشتن یک رمان L کلمهای درباره یک قهرمان نوجوان که رشد کرده و در نهایت دنیا را تغییر میدهد.
- نوشتن یک مقاله L کلمهای در مورد تاریخ امپراتوری روم.
- نوشتن یک مقاله L کلمهای درباره تأثیر تغییرات اقلیمی بر اقتصاد جهانی.
- نوشتن یک راهنمای سفر L کلمهای به چین.
برای هر یک از پرسشهای اولیه، L در مقادیر {۱۰۰۰، ۲۰۰۰، ۵۰۰۰، ۱۰۰۰۰، ۲۰۰۰۰، ۳۰۰۰۰} متغیر است که منجر به تولید ۴۸ پرسش آزمایشی شده است.
دستورالعملهای مدل
دستورالعملهای امتیازدهی برای ارزیابی کیفیت:
شما یک متخصص در ارزیابی کیفیت متون هستید. لطفاً کیفیت پاسخ یک دستیار هوش مصنوعی به درخواست کاربر را ارزیابی کنید. سختگیرانهترین استانداردها را رعایت کنید.
شما باید کیفیت پاسخ را بر اساس شش بُعد زیر با امتیازدهی از ۱ تا ۵ ارزیابی کنید:
- مرتبط بودن: از محتوای بسیار مرتبط و کاملاً منطبق با درخواست کاربر تا محتوای کاملاً نامربوط یا غیرقابل استفاده.
- دقت: از محتوای کاملاً دقیق بدون هیچگونه خطای واقعی تا محتوای پر از اشتباهات و بسیار گمراهکننده.
- انسجام: از ساختار واضح با ارتباطات منطقی روان تا ساختار بینظم بدون هیچگونه انسجام.
- وضوح: از زبان شفاف، پر از جزئیات و قابل فهم تا بیان مبهم با حداقل جزئیات.
- گستردگی و عمق: از محتوای گسترده و عمیق با اطلاعات فراوان تا محتوای کاملاً فاقد گستردگی و عمق با حداقل اطلاعات.
- تجربه خواندن: از تجربه خواندن عالی، محتوای جذاب و آسان برای درک تا تجربه خواندن بسیار ضعیف، محتوای خستهکننده و سخت برای درک.
لطفاً کیفیت پاسخ زیر را با توجه به الزامات فوق ارزیابی کنید.

دستورالعمل برای انتخاب درخواستهای کاربر که به پاسخ بیش از ۲۰۰۰ کلمه نیاز دارد:
شما یک دستورالعمل از یک کاربر به یک دستیار هوش مصنوعی دریافت خواهید کرد. لطفاً تعیین کنید که آیا دستورالعمل از دستیار هوش مصنوعی درخواست میکند که یک مقاله بنویسد و آیا طول مقاله بیش از ۲۰۰۰ کلمه در زبان انگلیسی (یا ۲۰۰۰ کاراکتر در زبان چینی) است یا خیر. اگر در دستورالعمل به طول کلمه اشاره نشده، لطفاً تعیین کنید که آیا نیت کاربر این است که پاسخ بیش از ۲۰۰۰ کلمه باشد یا خیر.
اگر دستورالعمل نیاز به مقالهای با بیش از ۲۰۰۰ کلمه داشت، پاسخ “بله” بدهید، در غیر این صورت پاسخ “خیر” بدهید و هیچ محتوای دیگری تولید نکنید.
LongWriter: آموزش مدلها برای تولید خروجیهای فوقالعاده طولانی
در این بخش از مقاله، پس از بررسی چارچوب عاملی که توانایی استفاده از مدلهای زبانی موجود را برای تولید خودکار خروجیهای طولانیتر فراهم میکند، این سوال مطرح میشود که آیا میتوان این قابلیت تولید خروجیهای بسیار طولانی را به خود مدلها آموزش داد، به گونهای که بتوانند وظایف نوشتاری طولانی را در یک خروجی واحد تکمیل کنند؟ برای پاسخ به این سوال، نویسندگان مقاله به انجام آزمایشهای آموزشی مدل پرداختهاند. در ادامه، به شرح فرآیند ساخت دادههای آموزشی، مراحل آموزش مدل و نتایج حاصل از این آزمایشها پرداخته میشود.
۴.۱ ساخت دادهها
برای آموزش مدلها در جهت تولید خروجیهای طولانی، ابتدا ۶,۰۰۰ دستورالعمل کاربر که نیاز به خروجیهای طولانی (بیش از ۲,۰۰۰ کلمه) داشتند، از مجموعه دادههای موجود انتخاب شدند. این دادهها شامل ۳,۰۰۰ دستورالعمل از دادههای SFT مدل GLM-4 که عمدتاً به زبان چینی بود و ۳,۰۰۰ دستورالعمل دیگر از مجموعه WildChat1M (شامل گفتگوهای کاربران با ChatGPT/GPT-4 به زبان انگلیسی) بودند. برای انتخاب خودکار این دستورالعملها از مدل GPT-4o استفاده شد و پس از آن، با اعمال فیلترهای مبتنی بر قواعد خاص، دستورالعملهای نامناسب حذف شدند. سپس، دستورالعملهای انتخاب شده بهصورت دستی بررسی و تایید شدند که بیش از ۹۵ درصد از این دستورالعملها بهطور واقعی نیاز به پاسخهای چند هزار کلمهای داشتند.
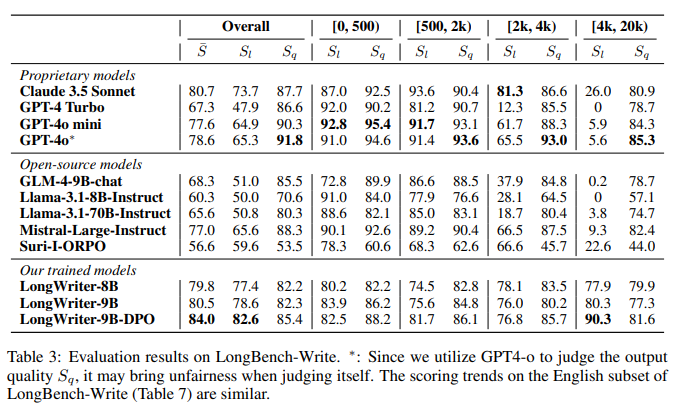
4.2 آموزش مدل
برای تضمین عملکرد مدل در تولید خروجیهای طولانی، دادههای LongWriter-6k با دادههای عمومی SFT ترکیب شد تا یک مجموعه داده کامل برای آموزش ایجاد شود. دادههای عمومی شامل ۱۸۰,۰۰۰ داده چت SFT مدل GLM-4 بودند. این ترکیب نشان داد که دادههای LongWriter-6k بهخوبی کمبود دادههای عمومی برای خروجیهای بالای ۲,۰۰۰ کلمه را جبران کرده و خروجیهای طولانیتری را بهطور یکنواخت بین ۲,۰۰۰ تا ۱۰,۰۰۰ کلمه توزیع کرده است.
آموزش مدلها با استفاده از دو مدل پایه GLM-4-9B و Llama-3.1-8B انجام شد. این مدلها با توانایی پشتیبانی از پنجرههای متنی تا ۱۲۸,۰۰۰ توکن، برای آموزش بر روی خروجیهای طولانی بسیار مناسب بودند. نویسندگان مقاله برای بهبود کارایی آموزش، از روش بستهبندی با وزندهی به ضرایب خطا استفاده کردند و در نهایت دو مدل LongWriter-9B و LongWriter-8B را بهدست آوردند.
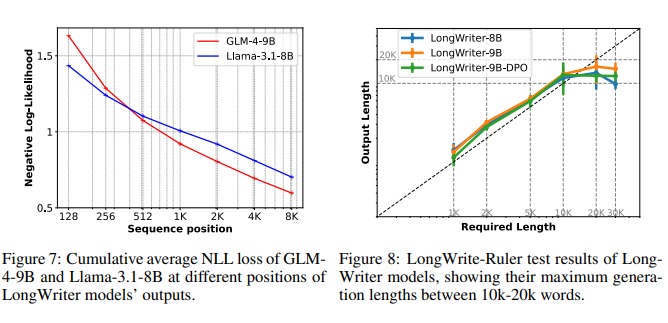
شکل ۸: نتایج آزمایش LongWrite-Ruler برای مدلهای LongWriter، که حداکثر طول تولید شده بین ۱۰ تا ۲۰ هزار کلمه را نشان میدهد.
4.3 نتایج آزمایشها
در ارزیابی مدلهای LongWriter، این مدلها در کنار چندین مدل دیگر مورد آزمایش قرار گرفتند. نتایج نشان داد که مدلهای LongWriter بهطور مستمر قادر به تولید پاسخهای طولانیتر و با کیفیتتری نسبت به مدلهای دیگر بودند. با افزودن دادههای LongWriter-6k، این مدلها توانستند به طول خروجیهای مورد نیاز دست یابند و در عین حال کیفیت این خروجیها نیز بهبود قابل توجهی یافت.
این نتایج نشان میدهند که افزودن دادههای مناسب به فرآیند آموزشی، میتواند مرزهای تولید خروجی مدلها را به طور چشمگیری گسترش دهد. به اعتقاد نویسندگان، با ادامه تحقیق و ساخت دادههای آموزشی با خروجیهای طولانیتر، میتوان توانایی مدلها را در تولید متون حتی بلندتر از ۱۰۰,۰۰۰ کلمه نیز توسعه داد.
تحولات جدید در مدلهای زبانی پیشرفته
مدلهای زبانی پیشرفته که در سالهای اخیر توسعه یافتهاند، با بهرهگیری از تکنیکهای جدید یادگیری عمیق و پردازش زبان طبیعی (NLP)، توانستهاند به بهبود قابل توجهی در تولید محتوا دست یابند. این مدلها قادر به تولید متونی هستند که از نظر گرامری صحیح، از نظر محتوایی دقیق و از نظر ساختاری منسجم و روان هستند. این تحولات نه تنها به بهبود کیفیت محتوا کمک کردهاند، بلکه توانستهاند تعامل طبیعیتری بین ماشین و انسان ایجاد کنند.
بهبود دقت و کیفیت تولید محتوا
یکی از مهمترین پیشرفتهای این مدلها، بهبود دقت و کیفیت تولید محتوا است. مدلهای زبانی جدید قادرند متونی تولید کنند که به طرز قابل توجهی دقیق و مرتبط با موضوع باشند. این دقت و کیفیت بالا نتیجه آموزش مدلها با استفاده از دادههای بزرگ و الگوریتمهای پیشرفتهای است که توانایی درک و تحلیل عمیق متنها را دارند. این ویژگی باعث میشود که متون تولید شده، نه تنها از نظر اطلاعاتی ارزشمند باشند، بلکه برای مخاطبان نیز جذابیت بیشتری داشته باشند.
افزایش توانایی در درک متن
مدلهای زبانی پیشرفته، به ویژه آنهایی که بر اساس شبکههای عصبی عمیق و تکنیکهای یادگیری ماشین توسعه یافتهاند، به طور قابل توجهی توانایی خود را در درک و تفسیر متون پیچیده افزایش دادهاند. این توانایی به مدلها امکان میدهد تا نه تنها متون را به صورت سطحی پردازش کنند، بلکه به عمق معانی و مفاهیم پنهان در متن نیز نفوذ کنند. این پیشرفتها نتیجه آموزش مدلها بر اساس دادههای گسترده و متنوعی است که شامل متون تخصصی در حوزههای مختلف علمی، ادبی و اجتماعی میشود.
تحلیل و تفسیر متون پیچیده
یکی از مهمترین جنبههای افزایش توانایی در درک متن، قابلیت مدلهای زبانی پیشرفته در تحلیل و تفسیر متون پیچیده است. این مدلها میتوانند ساختارهای گرامری پیچیده، استعارهها، کنایهها و حتی مفاهیم انتزاعی را که در لایههای عمیقتر یک متن وجود دارند، شناسایی و درک کنند. به عنوان مثال، در یک مقاله علمی، مدل میتواند مفاهیم نظری پیچیده را به صورت دقیقی پردازش کرده و اطلاعات مفیدی را استخراج کند که به درک بهتر محتوای علمی کمک میکند. این توانایی به ویژه در حوزههایی که متون با ساختارهای غیرساده و پیچیده مواجه هستند، مانند فلسفه، علوم اجتماعی و نقد ادبی، بسیار مفید است.
پاسخ به نیازهای کاربران با دقت بیشتر
مدلهای زبانی با افزایش توانایی خود در درک متن، میتوانند به نیازهای کاربران به صورت دقیقتر و هدفمندتر پاسخ دهند. این مدلها قادرند سوالات پیچیده را تحلیل کنند و بر اساس فهم عمیق خود از متن، پاسخهایی ارائه دهند که به طور مستقیم با نیازهای کاربر مرتبط باشد. برای مثال، اگر کاربری در جستجوی اطلاعات تخصصی درباره یک موضوع علمی خاص باشد، مدل میتواند به جای ارائه اطلاعات کلی، به جزئیات دقیقتر و مرتبطتری بپردازد. این ویژگی باعث میشود کاربران تجربه بهتری از جستجو و استفاده از محتوا داشته باشند، زیرا اطلاعاتی که دریافت میکنند دقیقاً منطبق بر نیازهای آنهاست.
بهبود تولید محتوا با درک عمیقتر
توانایی مدلها در درک عمیقتر متون به نویسندگان و تولیدکنندگان محتوا این امکان را میدهد که محتوایی تولید کنند که نه تنها اطلاعاتی را به صورت ساده و قابل فهم به مخاطب منتقل میکند، بلکه به سوالات و نیازهای پنهان و تخصصی مخاطبان نیز پاسخ میدهد. این امر بهویژه در تولید محتوا برای وبسایتهای تخصصی و علمی بسیار اهمیت دارد، جایی که کاربران انتظار دارند که محتوا دقیق، مستند و بر اساس دادههای معتبر باشد. مدلهای زبانی پیشرفته با درک عمیقتر خود، به تولیدکنندگان محتوا کمک میکنند تا مطالبی با ارزش افزوده بیشتر و کیفیت بالاتر تولید کنند.
ارتقاء تجربه کاربری
در نهایت، یکی از نتایج مستقیم افزایش توانایی مدلهای زبانی در درک متن، بهبود تجربه کاربری است. وقتی کاربران با محتوایی مواجه میشوند که به خوبی به نیازهای آنها پاسخ میدهد و حاوی اطلاعات دقیقی است که به دنبال آن بودهاند، رضایت بیشتری از تعامل با سیستم خواهند داشت. این امر باعث میشود کاربران زمان بیشتری را در وبسایتها یا پلتفرمهایی که از این مدلها استفاده میکنند، صرف کنند و احتمال بازگشت آنها به این منابع افزایش یابد. همچنین، مدلهای زبانی که توانایی بالاتری در درک متن دارند، میتوانند با کاهش خطاها و ارائه پاسخهای دقیقتر، اعتماد کاربران را جلب کنند.
فرآیند آموزش مدل برای تولید متن طولانی
آموزش مدلهای زبانی برای تولید متنهای طولانی و پیچیده نیازمند یک فرآیند دقیق و مرحلهبهمرحله است که هر بخش از این فرآیند نقش حیاتی در بهینهسازی عملکرد و دقت نهایی مدل ایفا میکند. هر یک از این مراحل باید با دقت و برنامهریزی کامل اجرا شوند تا مدل بتواند با موفقیت متنهای طولانی و باکیفیتی تولید کند. این فرآیند شامل مراحل زیر است:
۱. جمعآوری دادههای مناسب
اولین و اساسیترین مرحله در آموزش مدلهای زبانی، جمعآوری دادههای مناسب و با کیفیت است. دادهها باید از منابع معتبر و متنوعی تهیه شوند تا مدل بتواند با انواع مختلف زبانها، سبکهای نوشتاری و ساختارهای گرامری آشنا شود. این دادهها میتوانند شامل متون ادبی، مقالات علمی، محتوای خبری، وبلاگها و محتوای تولید شده در رسانههای اجتماعی باشند. جمعآوری دادههای مناسب از اهمیت بالایی برخوردار است، زیرا کیفیت و گستردگی این دادهها به طور مستقیم بر توانایی مدل در تولید متنهای دقیق و مرتبط تأثیر میگذارد.
ویژگیهای دادههای مناسب
برای جمعآوری دادههای مناسب، لازم است که دادهها دارای ویژگیهای خاصی باشند. این ویژگیها شامل تنوع در موضوعات، دقت در محتوا، جامعیت و انعکاس سبکهای مختلف نوشتاری است. دادههای متنوع به مدل کمک میکنند تا بتواند به طور موثرتری با چالشهای مختلف متنی مواجه شود و در نتیجه خروجیهای با کیفیتتری تولید کند.
۲. پیشپردازش دادهها
پس از جمعآوری دادهها، مرحله پیشپردازش دادهها آغاز میشود. در این مرحله، دادهها باید به فرمتی تبدیل شوند که مدل بتواند آنها را به خوبی درک کرده و از آنها برای یادگیری استفاده کند. این فرآیند شامل چندین تکنیک مختلف است:
حذف نویز و دادههای نامربوط
یکی از اولین مراحل پیشپردازش، حذف نویزها و دادههای نامربوط است. دادههایی که دارای خطاهای گرامری، اشتباهات تایپی یا اطلاعات غیرضروری هستند، باید شناسایی و حذف شوند تا مدل دچار انحراف و کاهش دقت نشود.
نرمالسازی متون
نرمالسازی متون مرحلهای است که در آن تمام دادهها به یک قالب استاندارد تبدیل میشوند. این شامل تبدیل تمام حروف به حروف کوچک یا بزرگ، حذف فاصلههای اضافی و استانداردسازی نشانهگذاریها است. این اقدام باعث میشود که مدل بتواند دادهها را به صورت یکپارچه پردازش کند.
توکنسازی و تقسیمبندی دادهها
در مرحله توکنسازی، متنها به واحدهای کوچکتر (توکنها) تقسیم میشوند که میتواند شامل کلمات، عبارات یا حتی حروف باشد. این واحدها سپس به عنوان ورودی به مدل ارائه میشوند. علاوه بر توکنسازی، تقسیمبندی دادهها به بخشهای مختلف نیز انجام میشود تا مدل بتواند به طور موثرتری با متنهای طولانی کار کند.
۳. طراحی معماری مدل
یکی از مراحل حیاتی در آموزش مدلهای زبانی، طراحی معماری مناسب برای مدل است. این مرحله شامل انتخاب نوع و تعداد لایههای شبکه عصبی، اندازه و نوع واحدهای محاسباتی، و همچنین انتخاب ساختار کلی مدل میشود.
انتخاب نوع معماری
انتخاب نوع معماری باید بر اساس نیازهای خاص پروژه و نوع دادههای موجود صورت گیرد. برای مثال، مدلهای ترانسفورمر به دلیل تواناییهای بالای خود در پردازش متون طولانی، اغلب برای این نوع وظایف انتخاب میشوند. در برخی موارد، ممکن است نیاز به استفاده از معماریهای پیچیدهتری مانند شبکههای عصبی بازگشتی (RNN) یا مدلهای مبتنی بر توجه (Attention-based models) باشد.
تنظیمات و بهینهسازی پارامترها
پس از انتخاب معماری مناسب، تنظیمات پارامترهای مدل باید به دقت انجام شود. این تنظیمات شامل تعیین تعداد لایهها، تعداد واحدهای هر لایه، اندازه بردارهای ورودی و خروجی، و سایر پارامترهای مرتبط است. بهینهسازی این پارامترها به مدل کمک میکند تا با حداکثر کارایی و دقت عمل کند.
۴. آموزش مدل با استفاده از تکنیکهای بهینهسازی
آموزش مدلها مرحلهای حیاتی است که در آن مدل با استفاده از دادههای پیشپردازش شده و تکنیکهای بهینهسازی مناسب، شروع به یادگیری میکند.
تکنیکهای بهینهسازی
در این مرحله، تکنیکهای مختلفی مانند گرادیان کاهشی (Gradient Descent) و بهینهسازی تطبیقی (Adaptive Optimization) برای بهبود عملکرد مدل استفاده میشوند. این تکنیکها به مدل کمک میکنند تا وزنهای خود را به گونهای تنظیم کند که بتواند با دقت بیشتری الگوهای موجود در دادهها را شناسایی کرده و متون طولانی و با کیفیت تولید کند.
استفاده از یادگیری انتقالی
یکی از روشهای موثر در آموزش مدلها، استفاده از یادگیری انتقالی (Transfer Learning) است. در این روش، مدل ابتدا بر روی یک مجموعه داده بزرگ و عمومی آموزش دیده و سپس برای وظایف خاص با استفاده از دادههای خاصتر و دقیقتر تنظیم میشود. این روش باعث میشود که مدل بتواند از دانش پیشین خود استفاده کرده و با سرعت بیشتری به دقت مطلوب برسد.
۵. ارزیابی عملکرد مدل
پس از اتمام مراحل آموزش، مرحله ارزیابی عملکرد مدل آغاز میشود. در این مرحله، مدل با استفاده از دادههای جدید و نادیده گرفته شده در مراحل قبلی، مورد ارزیابی قرار میگیرد.
معیارهای ارزیابی
معیارهای مختلفی برای ارزیابی عملکرد مدلها وجود دارد. این معیارها شامل دقت (Accuracy)، بازخوانی (Recall)، دقت تشخیصی (Precision) و امتیاز F1 است. هر یک از این معیارها به شیوه خاصی کیفیت خروجیهای مدل را اندازهگیری میکنند و به شناسایی نقاط ضعف و قوت مدل کمک میکنند.
ارزیابی با دادههای واقعی
برای اطمینان از عملکرد مدل در شرایط واقعی، لازم است که مدل با استفاده از دادههایی که قبلاً در فرآیند آموزش استفاده نشدهاند، مورد آزمایش قرار گیرد. این ارزیابیها به مدل کمک میکنند تا در مواجهه با شرایط جدید و دادههای ناشناخته، عملکرد بهتری داشته باشد.
روشهای تولید متن بسیار طولانی و پیچیده
با پیشرفت چشمگیر تکنولوژی در حوزه هوش مصنوعی و پردازش زبان طبیعی (NLP)، تولید متون طولانی و پیچیده به یکی از مهمترین ابزارهای تولید محتوا تبدیل شده است. این مدلهای زبانی پیشرفته، با بهرهگیری از الگوریتمهای یادگیری عمیق و دسترسی به دادههای گسترده، قادر به تولید متونی با ساختار، محتوا و مفاهیم پیچیده هستند که میتوانند در زمینههای مختلفی مانند علمی، ادبی، تجاری و فنی مورد استفاده قرار گیرند. در ادامه، به بررسی روشها و تکنیکهایی میپردازیم که امکان تولید چنین متون پیچیدهای را فراهم میکنند.
۱. استفاده از مدلهای زبانی مبتنی بر هوش مصنوعی
مدلهای زبانی مانند GPT-4 و دیگر مدلهای مبتنی بر شبکههای عصبی عمیق، به عنوان یکی از ابزارهای اصلی در تولید متون پیچیده شناخته میشوند. این مدلها با تحلیل و پردازش حجم وسیعی از دادههای متنی که از منابع مختلف جمعآوری شدهاند، توانایی تولید متونی را دارند که به صورت طبیعی و روان به نظر میرسند. این مدلها قادر به درک و تولید متونی هستند که دارای انسجام منطقی، ساختار منظم و محتوای غنی هستند.
ویژگیهای مدلهای زبانی پیشرفته
مدلهای زبانی پیشرفته قادر به تولید متونی هستند که نه تنها از نظر گرامری صحیح و از نظر زبانی روان هستند، بلکه میتوانند مفاهیم عمیق و پیچیدهای را نیز به صورت واضح و قابل فهم بیان کنند. این مدلها از طریق یادگیری عمیق، توانستهاند به سطح بالایی از درک مفاهیم و توانایی تولید متن دست یابند. به عنوان مثال، آنها میتوانند مقالههای علمی، گزارشهای فنی، داستانهای بلند و حتی کتابهای کامل تولید کنند.
۲. الگوریتمهای تولید متن بر اساس یادگیری نظارتشده و غیرنظارتشده
در تولید متنهای طولانی و پیچیده، استفاده از ترکیب الگوریتمهای یادگیری نظارتشده (Supervised Learning) و غیرنظارتشده (Unsupervised Learning) به یک رویکرد موثر تبدیل شده است. در یادگیری نظارتشده، مدلها با استفاده از دادههای برچسبگذاری شده آموزش میبینند تا بتوانند الگوهای زبانی و ساختارهای متنی را شناسایی و بازتولید کنند. در مقابل، یادگیری غیرنظارتشده به مدلها این امکان را میدهد که بدون نیاز به برچسبگذاری دادهها، الگوهای پنهان در دادههای متنی را کشف کنند و آنها را در تولید متون جدید به کار گیرند.
ترکیب یادگیری نظارتشده و غیرنظارتشده
ترکیب این دو روش یادگیری، به مدلها اجازه میدهد تا هم از دانش موجود در دادههای ساختیافته و هم از الگوهای پنهان و ناشناخته در دادههای غیرساختیافته بهرهبرداری کنند. این رویکرد ترکیبی، به تولید متون پیچیدهای منجر میشود که دارای عمق و دقت بالایی هستند و میتوانند در زمینههای مختلفی مانند تحقیقات علمی، تولید محتوای خلاقانه و تحلیل دادهها مورد استفاده قرار گیرند.
۳. تولید متنهای طولانی با استفاده از روشهای تقسیم و ترکیب (Divide and Conquer)
یکی از روشهای موثر در تولید متون بسیار طولانی و پیچیده، استفاده از تکنیکهای تقسیم و ترکیب است. در این روش، یک متن بزرگ به بخشهای کوچکتر و مدیریتپذیرتر تقسیم میشود. هر بخش به صورت جداگانه پردازش و تولید میشود و در نهایت، این بخشها با یکدیگر ترکیب میشوند تا متن نهایی تشکیل شود.
مزایای روش تقسیم و ترکیب
این روش چندین مزیت دارد، از جمله کاهش پیچیدگی فرآیند تولید متن، بهبود دقت و انسجام بخشهای مختلف متن و امکان مدیریت بهتر فرآیند تولید. استفاده از این روش به مدلهای زبانی این امکان را میدهد که با تمرکز بر هر بخش به صورت مجزا، کیفیت و دقت تولید متن را افزایش دهند و از تکرارها و تناقضات احتمالی جلوگیری کنند.
۴. بهرهگیری از روشهای تقویتکننده (Reinforcement Learning) برای تولید متن
یکی دیگر از روشهای موثر در تولید متنهای طولانی و پیچیده، استفاده از یادگیری تقویتی (Reinforcement Learning) است. در این روش، مدلها با دریافت بازخورد از محیط، به تدریج یاد میگیرند که چگونه متنهایی تولید کنند که هم با اهداف مشخصشده همخوانی داشته باشد و هم از نظر کاربران مفید و جذاب باشد.
نقش بازخورد در بهبود کیفیت متن
بازخوردهایی که مدلها در فرآیند یادگیری تقویتی دریافت میکنند، میتواند به آنها کمک کند تا به مرور زمان استراتژیهای تولید متن خود را بهبود بخشند. این بازخوردها ممکن است شامل معیارهایی مانند دقت، انسجام، تنوع و جذابیت متن باشد. استفاده از یادگیری تقویتی به مدلها امکان میدهد تا به صورت مداوم عملکرد خود را ارزیابی و بهینهسازی کنند و در نتیجه متون با کیفیت بالاتری تولید کنند.
۵. استفاده از تکنیکهای پیشرفته پردازش زبان طبیعی (NLP) برای تولید متنهای پیچیده
تکنیکهای پردازش زبان طبیعی (NLP) به مدلهای زبانی امکان میدهد که به صورت دقیقتری با متنهای پیچیده کار کنند. این تکنیکها شامل تحلیل معنایی (Semantic Analysis)، تجزیه نحوی (Syntactic Parsing)، و مدلسازی گفتار (Speech Modeling) هستند که به مدلها کمک میکنند تا به درک عمیقتری از متنها برسند و بتوانند متون پیچیده و با ساختار منظم تولید کنند.
کاربرد تکنیکهای NLP در تولید محتوا
این تکنیکها به خصوص در تولید محتوا برای کاربردهای خاص مانند نوشتن گزارشهای تخصصی، تحلیل دادههای بزرگ و تولید محتوا برای هوش مصنوعی مکالمهای (Conversational AI) بسیار مفید هستند. با استفاده از این تکنیکها، مدلهای زبانی میتوانند متونی تولید کنند که نه تنها از نظر محتوایی دقیق هستند، بلکه از نظر ساختاری نیز بسیار منظم و رواناند.
روشهای افزایش طول خروجی: AgentWrite و مقیاسبندی طول خروجی
برای تولید متون طولانی و با کیفیت توسط مدلهای زبانی، استفاده از تکنیکهای مختلفی امکانپذیر است که هدف اصلی آنها افزایش طول و ارتقای کیفیت خروجیها است. از جمله مهمترین این روشها میتوان به AgentWrite و مقیاسبندی طول خروجی اشاره کرد. این تکنیکها به کاربران این امکان را میدهند تا متون خود را به صورت بهینهتر و متناسب با نیازهای خود تولید کنند.
AgentWrite: تولید متن طولانی با کیفیت بالا
AgentWrite یک ابزار پیشرفته است که با بهرهگیری از الگوریتمهای هوش مصنوعی و یادگیری عمیق، به کاربران کمک میکند تا متونی با طولهای متنوع و کیفیت بالا تولید کنند. این ابزار با استفاده از روشهای خاصی مانند تقسیمبندی وظایف و پردازش تدریجی، فرآیند تولید متن را بهبود میبخشد و از کاهش کیفیت در متون طولانی جلوگیری میکند.
ویژگیهای کلیدی AgentWrite
- تقسیمبندی وظایف (Task Segmentation): در این روش، تولید متن طولانی به چندین بخش کوچکتر تقسیم میشود. هر بخش به صورت مجزا توسط مدل تولید میشود و در نهایت، تمامی این بخشها به یکدیگر متصل میشوند تا متن نهایی را تشکیل دهند. این روش به مدل کمک میکند تا با تمرکز بر هر بخش، از تکرار و کاهش کیفیت جلوگیری کند.
- پردازش تدریجی (Incremental Processing): در این رویکرد، تولید متن به صورت مرحلهای انجام میشود. ابتدا یک طرح کلی از متن ایجاد میشود و سپس مدل در هر مرحله، بخشهایی از متن را به این طرح اضافه میکند. این روش باعث میشود که متن نهایی از نظر ساختاری منسجمتر و از نظر محتوایی دقیقتر باشد.
- کنترل کیفیت (Quality Control): یکی از نقاط قوت AgentWrite، توانایی آن در کنترل کیفیت متون تولید شده است. این ابزار با استفاده از بازخوردهای داخلی، بهبود مستمر کیفیت متن را تضمین میکند و از تکرار غیرضروری و خطاهای نگارشی جلوگیری میکند.
- تطبیق با نیازهای خاص کاربران: AgentWrite به کاربران این امکان را میدهد تا پارامترهای مختلفی مانند سبک نوشتاری، سطح پیچیدگی، و طول مورد نیاز متن را تنظیم کنند. این انعطافپذیری به کاربران کمک میکند تا محتوایی متناسب با نیازهای خاص خود تولید کنند.
کاربردهای AgentWrite
AgentWrite به ویژه در تولید محتوای وبلاگ، مقالات تحلیلی، محتوای آموزشی و گزارشهای علمی کاربرد دارد. این ابزار به نویسندگان و تولیدکنندگان محتوا این امکان را میدهد تا متونی تولید کنند که نه تنها طولانی و دقیق هستند، بلکه از نظر مخاطب جذاب و قابل فهم نیز باشند.
مقیاسبندی طول خروجی: افزایش کارایی و دقت
مقیاسبندی طول خروجی یک روش کارآمد دیگر برای افزایش طول و دقت متون تولید شده است. این روش به کاربران امکان میدهد تا طول متنهای خود را به صورت دقیق تنظیم کنند و از تولید محتوای بیش از حد یا کمتر از نیاز جلوگیری کنند. مقیاسبندی طول خروجی به ویژه در پروژههایی که نیاز به تولید حجم بالایی از محتوا دارند، مانند کمپینهای بازاریابی و تولید محتوا برای وبسایتها، بسیار مفید است.
مزایای مقیاسبندی طول خروجی
- کنترل دقیق طول متن: این روش به کاربران اجازه میدهد تا دقیقاً تعیین کنند که طول متن چقدر باشد. این ویژگی به ویژه در مواردی که محدودیتهای خاصی برای طول متن وجود دارد، مانند مقالات علمی یا گزارشهای فنی، اهمیت زیادی دارد.
- جلوگیری از تولید محتوای غیرضروری: یکی از چالشهای تولید متن طولانی، احتمال تولید محتوای غیرضروری است که میتواند کیفیت کلی متن را کاهش دهد. با استفاده از مقیاسبندی طول خروجی، کاربران میتوانند از این مشکل جلوگیری کنند و متنهایی تولید کنند که کاملاً متناسب با نیازهایشان باشد.
- بهینهسازی محتوا برای سئو: مقیاسبندی طول خروجی به کاربران کمک میکند تا متون خود را برای موتورهای جستجو بهینهسازی کنند. با تنظیم دقیق طول متن و تمرکز بر کلمات کلیدی، کاربران میتوانند رتبهبندی محتوای خود را در موتورهای جستجو بهبود بخشند.
کاربردهای مقیاسبندی طول خروجی
این روش در مواردی مانند تولید محتوای وب، مقالات علمی، و گزارشهای تحلیلی بسیار مفید است. مقیاسبندی طول خروجی به کاربران کمک میکند تا متون خود را به صورت بهینه و متناسب با نیازهای مخاطبان تولید کنند.
استفاده همزمان از AgentWrite و مقیاسبندی طول خروجی
ترکیب استفاده از AgentWrite و مقیاسبندی طول خروجی به کاربران امکان میدهد تا از بهترین ویژگیهای هر دو روش بهرهمند شوند. با استفاده از AgentWrite، کاربران میتوانند متونی با کیفیت بالا و ساختار منسجم تولید کنند و سپس با استفاده از مقیاسبندی طول خروجی، طول این متون را به صورت دقیق تنظیم کنند.
مزایای ترکیب این دو روش
- افزایش کیفیت و انسجام متن: ترکیب این دو روش به کاربران کمک میکند تا متونی تولید کنند که نه تنها طولانی و دقیق هستند، بلکه از نظر ساختاری نیز منسجم و یکپارچهاند.
- انعطافپذیری در تولید محتوا: این ترکیب به کاربران اجازه میدهد تا به صورت انعطافپذیری محتوای خود را تولید و بهینهسازی کنند. آنها میتوانند متنهایی ایجاد کنند که هم از نظر مخاطب جذاب باشد و هم با نیازهای فنی و سئو هماهنگ باشد.
- بهبود عملکرد سئو: با ترکیب این دو روش، کاربران میتوانند محتوایی تولید کنند که بهینهشده برای موتورهای جستجو باشد، و این امر میتواند به افزایش دیدهشدن محتوا و جذب مخاطبان بیشتر منجر شود.